
Like Tensorflow, Mediapipe is a framework used to build machine learning models and deploy them. The model we will be talking about in this blog is Mediapipe’s Hand landmark model that is trained on over 30K real life images. Mediapipe is the perfect API because it is light weight and it contains everything you need to deploy mobile, web, edge and IoT with ease!
Before we get into that, let’s take a quick look at the Flo Edge One,
a must-have in every AI and robotics engineer’s toolbox. Here are some
remarkable benchmarks that make it a top competitor in edge devices!
- Pre-installed with Ubuntu 22.04 and tools like ROS2, OpenCV, TFlite, etc.
- Qualcomm Adreno 630 GPU.
- 12 MP 4k camera at up to 30fps
- Inferencing the model at 200 milliseconds (CPU) producing a smooth output of around 10 fps.
Introduction:
The hand landmark model bundle on mediapipe lets you detect landmarks of the hand in an image. Specifically, the outputs would include handedness (left/right hand) and landmarks (fingers, tips, dips, etc.).

This model bundle consists of two models – a palm detection model and a hand landmarking model. Hand pose detection has really cool real life applications including virtual reality. We are no Iron Man and we may not have a suit to control with gestures but we sure can find a lot of incredible applications for this model! And who knows, maybe we’ll get around to making a suit as well 👀️ Stay with us and find out.
Dataset and Models:
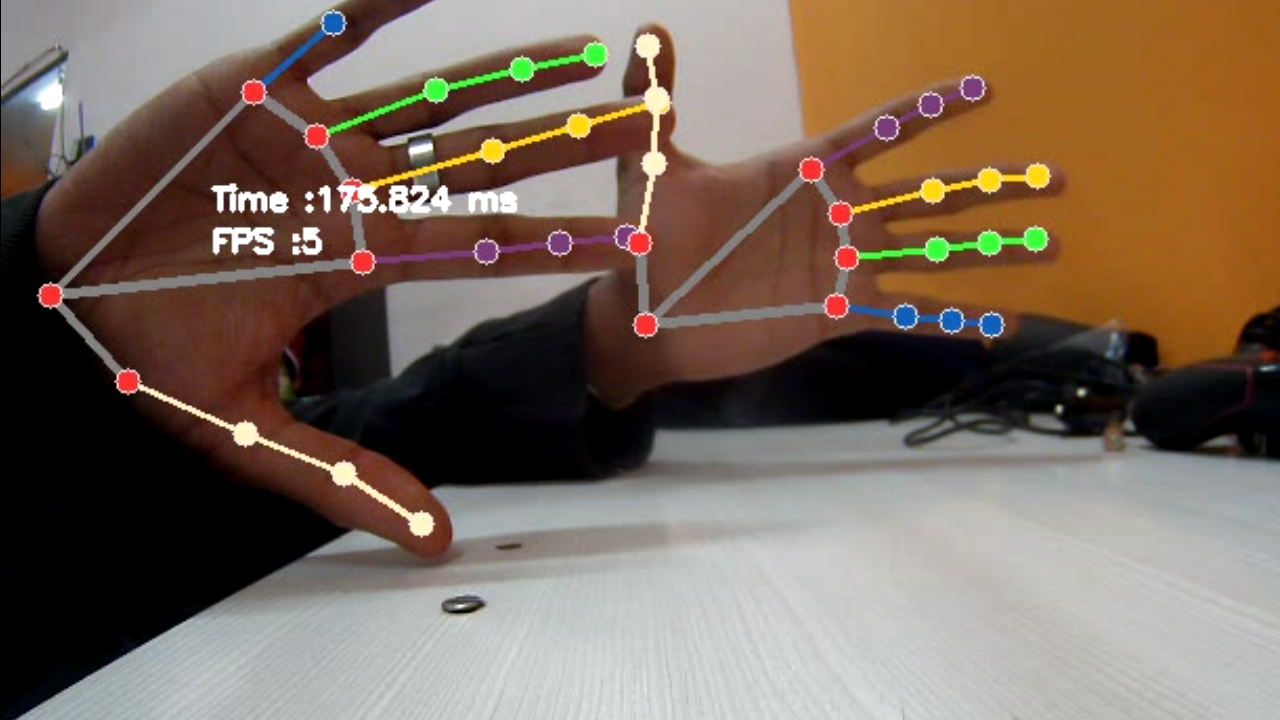
This model come pretrained on over 30, 000 different real life images as well as several rendered hand pose images over various backgrounds. On the detected hand region, it localizes 21 keypoints which include 3 points per finger, and 6 other points in the palm region, making it a total of 21. After the palm detection model finds the region in which the palm is located, the landmarking model detects the keypoints within the cropped region.

Since it is computationally heavy to constantly run the palm detection model on video or live stream, the landmarking model uses the bounding box produced for the current frame in all subsequent frames in order to localize. The bounding box is computed again only if the landmarking model fails to find a hand and all its keypoints in the current bounding box. Machine learning? More like Machine lazing.
Usage:
Another alternative to running this model efficiently is using the Flo Edge One GPU! What is Flo Edge One you ask? This impressive device boasts a light GPU that can deliver smooth results at around 20 FPS, all while maintaining a high level of accuracy. The Flo Edge One is truly a remarkable device, providing a plethora of impressive features that make it a must-have for tech enthusiasts. With its onboard camera, inbuilt IMU, and GNSS capabilities, this device truly has it all. It comes pre-installed with Ubuntu 22.04, ROS2, OpenCV, and various other tools, making it the perfect choice for your robotics ventures. The best part? Amidst the semiconductor crisis, the Flo Edge One is affordable and ready to ship! So you can get started ASAP, without breaking the bank.
Wanna make work interesting? Keep the edge on your tabletop with the camera pointing towards you, run this hand pose detection model alongside a script that translates all your hand gestures to keyboard and mouse movements and voila! You have yourself a virtually operated setup to show off at work.
Performance Analysis:
Being a heavy model, on CPU, the best we could get was 5 – 7 FPS. This performance can be highly improved by running it on the Flo Edge GPU and can give a satisfactory output of at least 10 – 13 FPS and an inference time of around 60 milliseconds.
The hand landmarking model happens to be one of the heaviest models on mediapipe. One of the reasons why the model is pretty heavy is because certain parts of the hands are detected individually and then they are all put together to obtain the output we see here. So for example, each of the fingers are detected and the parts of the palm are detected separately. On these detected paths, keypoints are drawn and then they’re all drawn together to form what we see as a pose model. Once this is done, the output is annotated in such a way that the landmarks are drawn on different parts of the hands and we have a total of 21 different parameters to mention. This is like putting together a jigsaw puzzle every single time the position of the hand changes with respect to the frame!
Conclusion:
The Hand landmarking model on mediapipe yields incredibly accurate pose detection results when run on a CPU or a GPU. But either way, it is a very computationally heavy model and realistically it can not give over 15 FPS while taking an input live stream or video. Regardless, it has really fun applications like VR and while it is still miles away from making you the next Iron Man, it’s like the man himself says “Sometimes you gotta run before you can walk”.

