
This is an introduction to a machine learning model called MiDaS that can be used with the Flo Edge One. You can easily use this model to create AI applications using Flo Edge as well as many other ready-to-use Flo Edge GPU models.
Before we get into that, let’s take a quick look at the Flo Edge One, a must-have in every AI and robotics engineer’s toolbox. Here are some remarkable benchmarks that make it a top competitor in edge devices!
- Pre-installed with Ubuntu 22.04 and tools like ROS2, OpenCV, TFlite, etc.
- Qualcomm Adreno 630 GPU.
- 12 MP 4k camera at up to 30fps
- Inferencing Midas at 57 milliseconds producing a smooth output of around 20 fps.
Introduction:
MiDaS is a machine learning model that estimates depth from an arbitrary input image.

Depth is an incredibly valuable parameter of the physical environment. It allows us to estimate the position of objects in a three-dimensional space, which is crucial for various applications. Monocular depth estimation is undoubtedly a useful technique, but it still poses a significant challenge for researchers and developers alike. In the world of autonomous vehicles, obtaining accurate results is crucial. To tackle this problem, LiDARs or stereo cameras have traditionally been used due to their ability to provide dense ground truth. However, it’s important to note that these sensor options can come with a hefty price tag and may require a complex deployment process.
I’m excited to share with you a cutting-edge machine learning algorithm called MiDaS. Its purpose is to predict the depth value of each pixel in a given RGB image. What’s impressive about MiDaS is that it’s been trained on multiple datasets, allowing it to accurately perform this task.
Dataset and Model:

Imagine a picture of several people standing in a straight line with a light bulb directly over only one person’s head, but this bulb is not included in the picture. How can you tell who’s standing closest to the bulb? That’s right! From their shadows – The one with no shadow is directly under the bulb and as the shadows grow, the distance of the person from the bulb must be increasing. Similar to how our brain picks up visual cues like this from an image, the Midas model is also trained on similar visual cues to estimate which object is closest to the camera. Let’s see how this is done.
Training the Midas model is the most essential part of the process in order to obtain accurate results. The way this model is trained is slightly different when compared to classical machine learning models. It requires two types of datasets – a sparse dataset and a labelled dataset.
Sparse dataset: This consists of straightforward monocular camera feed.
Labelled dataset: As in supervised learning, a dataset contained depth information, obtained from a measuring tool like LiDAR, laser Scanner, or stereo camera.
This is like giving someone a picture of a sphere and the actual sphere and asking them how far the sphere needs to be placed in order to match the scale in the image with respect to its surroundings. These datasets are used to train the model on the input data which is a single RGB image and its corresponding depth information which comes from the labelled dataset.
Loss function in MiDaS:

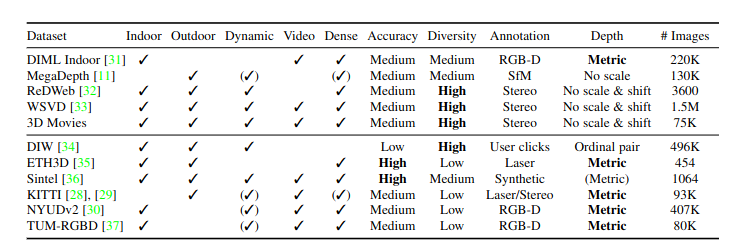
All existing datasets containing depth information have been accumulated from different measuring tools such as LiDARs, Stereo cameras, Laser scanners, etc. this leads to a variation among data, making it hard to find a large collection of uniform data to train the model on. Midas makes use of a loss function that absorbs these variations, thereby solving all compatibility issues and making it possible to train the model on multiple datasets simultaneously. This function is called the “scale and shift invariant loss function”, and to define a meaningful scale and shift invariant loss, the prediction and ground truth should be aligned with respect to their scale and shift. The function definition above basically represents this, where it finds the difference in the predicted and the ground truth and then optimizes to reduce this loss.
Given below is the function definition introduced by Midas.
All thanks to this function, Midas uses multiple datasets. As seen below, which makes it robust to a variety of environments and conditions.
Usage:
If you’re looking for a powerful and efficient way to run the Midas model, look no further than the Flo Edge One. This impressive device boasts a light GPU that can deliver smooth results at around 20 FPS, all while maintaining a high level of accuracy. The Flo Edge One is truly a remarkable device, providing a plethora of impressive features that make it a must-have for tech enthusiasts. With its onboard camera, inbuilt IMU, and GNSS capabilities, this device truly has it all. It comes pre-installed with Ubuntu 22.04, ROS2, OpenCV, and various other tools, making it the perfect choice for your robotics ventures. Take for example an industrial obstacle avoidance bot, obtaining geometric information of the environment has never been easier. Thanks to the onboard camera and Midas model running on the edge, you can accurately capture all the necessary details. And utilize it for implementing obstacle avoidance techniques while localizing using the other sensors built into the system. The best part? Amidst the semiconductor crisis, the Flo Edge One is affordable and ready to ship! So you can get started ASAP, without breaking the bank.
Performance Analysis:
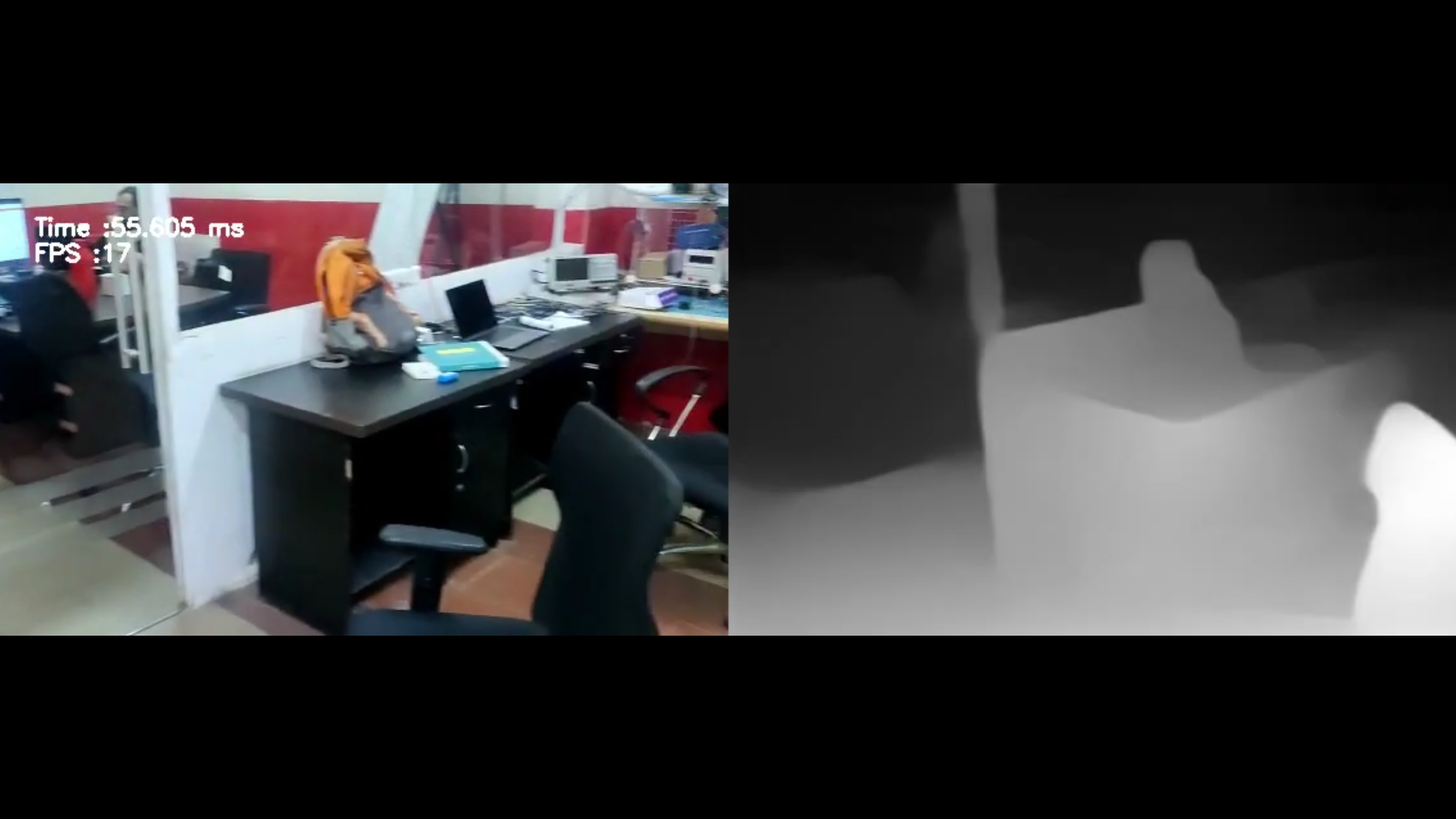
The model is capable of producing an impressive 57 millisecond inference time while running on the Flo Edge GPU. With an input stream of 30 FPS, we get an output of around 17 FPS and very accurate depth estimates. Here, the color scale used is black and white, where objects in white are closer than those in black. This color scale is just a preference, and can be easily switched as seen in the image below.

Conclusion:
The Midas model yields incredibly accurate depth results when run on the Flo Edge GPU even after being compressed as a .tflite model architecture. Coupled with the 12 MP onboard camera and inbuilt IMU, a wide range of object avoidance systems can be developed for use cases like surveillance, security, material handling, manufacturing, etc., at a greatly reduced cost.

